🚀 Accelerating Speculative Decoding in vLLM with Pipeline Parallelism
With the growing demand for fast, scalable large language model (LLM) inference, systems like vLLM have become essential infrastructure for serving models like LLaMA, Mistral, and Falcon. While vLLM has made impressive strides in efficient KV cache management and throughput, some features—like pipeline parallelism with speculative decoding—remained underdeveloped.
In our latest project, we tackled this head-on.
We extended vLLM V1 to support intra-node pipeline parallelism, EAGLE-style speculative decoding, and conducted a thorough exploration of 3D parallelism (data, tensor, pipeline). Our work brings together cutting-edge system design and empirical performance study to make high-throughput, low-latency LLM inference more accessible—even on a single machine.
🔍 Motivation
Speculative decoding accelerates inference by generating candidate tokens with a lightweight drafter model, then verifying them with the full model. Meanwhile, pipeline parallelism splits large models across GPUs for concurrent execution of different layers. But until now, no system offered a robust integration of both—especially for Eagle3-style speculative decoding, which introduces additional architectural demands.
With vLLM V1’s clean, modular codebase and built-in support for multiprocessing, we saw a clear opportunity to bridge the gap and unlock performance wins for both large and small models.
🏗️ Our Contributions
We focused on a single-node, multi-GPU setup and made the following core contributions:
- Pipeline-Parallel Engine Executor & Scheduler
We implemented a new pipeline-compatible executor and scheduler inside vLLM V1. This design supports both centralized and decentralized communication strategies, enabling better overlap between computation and communication.
- Speculative Decoding Integration
We integrated EAGLE3-style speculative decoding with pipeline execution—supporting inter-stage data transfer of mid-layer hidden states and placement optimizations for the drafter model.
- 3D Parallelism Evaluation
We evaluated combinations of data, pipeline, and tensor parallelism on 8x H100 GPUs, analyzing trade-offs for both small (8B) and large (70B) models.
🧠 System Design
Our pipeline system design includes:
- A centralized version for correctness validation.
- A decentralized version that reduces hidden state communication overhead and latency.
- Asynchronous scheduling to fully saturate the pipeline with multiple batches.
To support Eagle3 speculative decoding, we implemented mechanisms for:
- Propagating middle-layer activations (e.g., from LLaMA-3.1 layer 2, 19, 29).
- Re-embedding token IDs into hidden states across pipeline stages.
- Reducing inter-stage communication by co-locating the drafter and rejection sampler.
⚙️ Marrying Pipeline Parallelism with Speculative Decoding in vLLM
While vLLM V1 offers a clean, modular, and performant inference engine, it lacked support for integrating pipeline parallelism with speculative decoding. Our goal was to bridge that gap—with minimal disruption to the existing architecture and maximum flexibility for researchers and practitioners.
We designed and implemented a pipeline-compatible engine executor and scheduler, along with support for EAGLE3-style speculative decoding, paying special attention to inter-stage communication, draft token placement, and activation reuse across partitions.
Let’s walk through the architecture and the innovations behind our system.
🧩 Modular Enhancements to vLLM V1
vLLM V1 separates the frontend (LLMEngine) and the backend (EngineCore):
- Frontend: Handles request processing, tokenization, packaging outputs, and polling.
- Backend (EngineCore): Schedules requests, manages KV caches, launches workers, and dispatches batches.
We intercepted this flow to allow users to dynamically enable pipeline parallelism by specifying a config flag. When enabled, our custom pipeline-aware scheduler and executor modules replace the default ones.
This plug-and-play design ensures:
- Seamless integration without code duplication
- Compatibility with existing APIs
- Transparent support for both single-stage and multi-stage deployments
🔄 Centralized vs. Decentralized Pipeline Architectures
We implemented two distinct pipeline designs:
1. Centralized Design (Baseline)
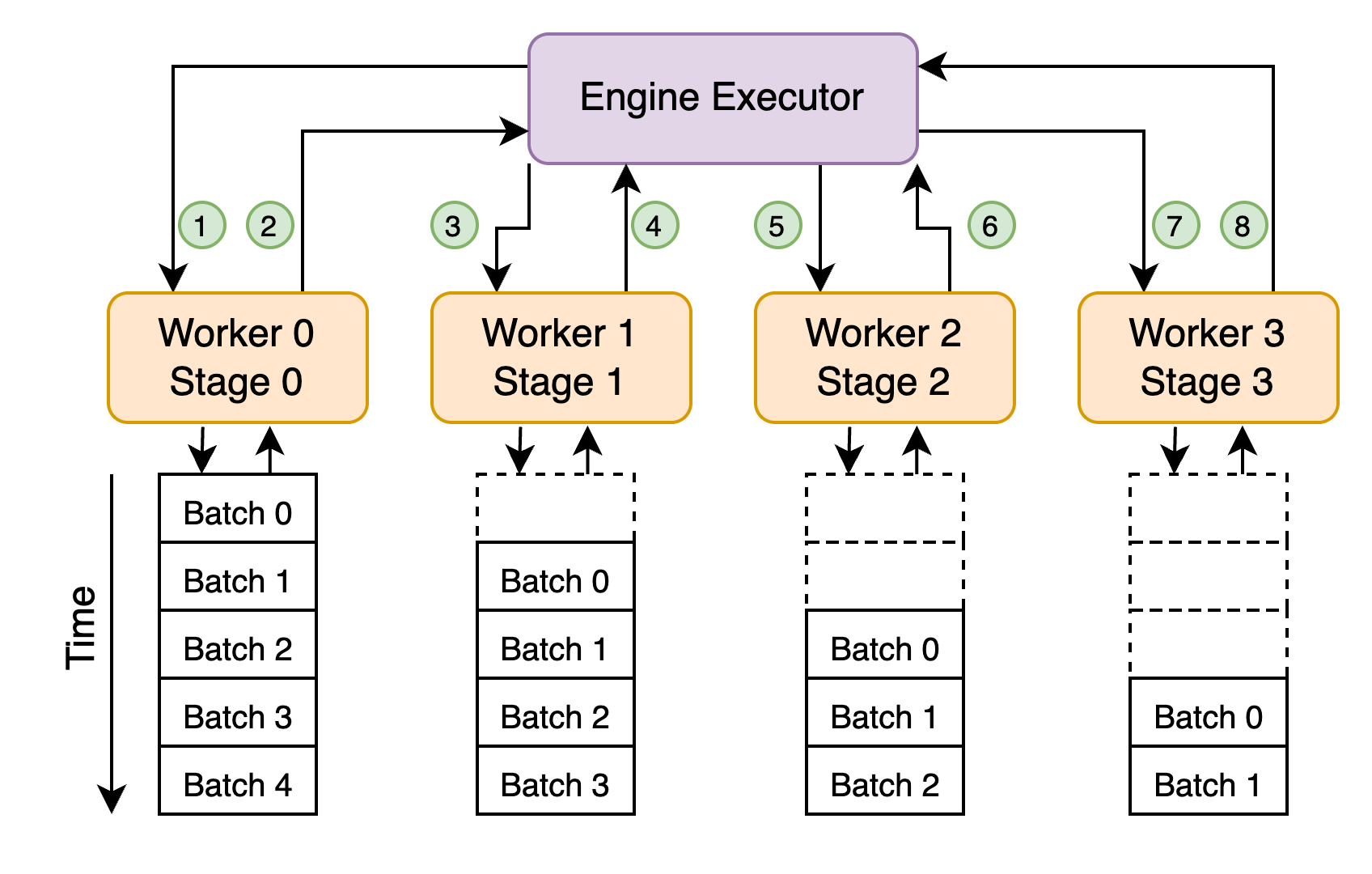
In this version, the EngineExecutor orchestrates both:
- Request scheduling
- Inter-stage communication (via explicit send/receive)
Pros:
- Easier to debug
- Ensures correct routing and backpressure control
Cons:
- Bottlenecked by centralized coordination
- Higher latency due to repeated roundtrips through executor
This design was critical for validating model partitioning and verifying inter-stage KV cache integrity.
2. Decentralized Design (Optimized)
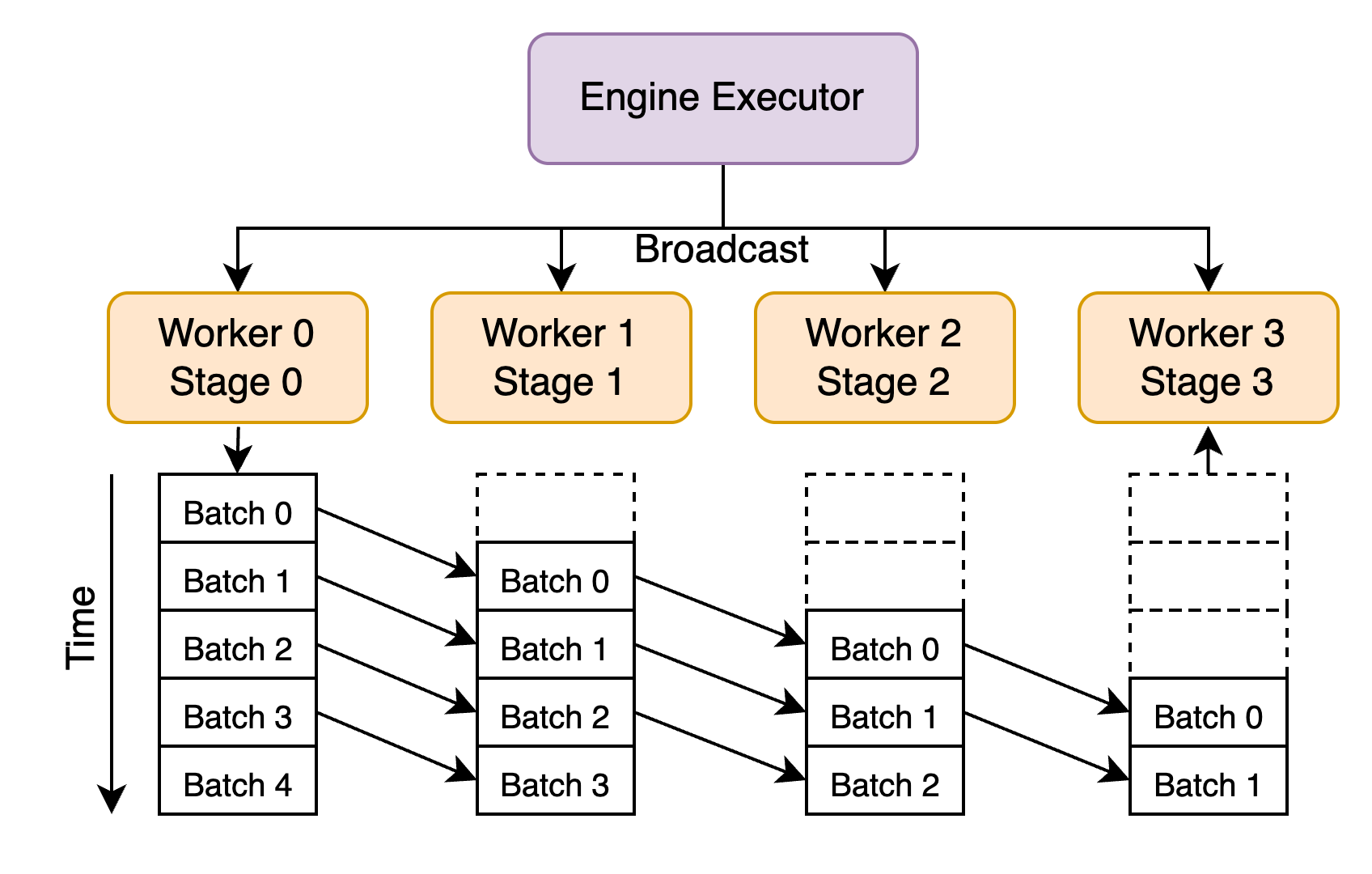
In this optimized version:
- Once a batch is scheduled, it is broadcast asynchronously to all pipeline stages
- Stages communicate directly using async collective RPCs (e.g., via NCCL, Gloo)
Benefits:
- Removes executor bottleneck
- Reduces unnecessary communication
- Enables better pipeline saturation
We also implemented:
- Asynchronous request tracking (avoiding duplicate scheduling)
- Batch memory tracking for cache reuse and state management
This design significantly lowered inference latency in our benchmarks and demonstrated scalability to 4+ pipeline stages.
🧠 Speculative Decoding with Pipeline Parallelism
Integrating speculative decoding into a pipelined system was non-trivial. EAGLE3 requires:
- Hidden states from specific intermediate layers (e.g., layers 2, 19, 29 in LLaMA3.1-8B)
- A drafter model that uses embeddings and partial logits to propose draft tokens
- A rejection sampler that rescans the draft tokens with the full model
We evaluated two placement strategies for the drafter model:
Option 1: Drafter at First Stage
- Natural pipeline: drafter → verifier
- But: vLLM couples drafter with rejection sampler tightly
- Result: final logits from last stage must be sent back to first stage → costly feedback loop
✅ Option 2: Drafter at Final Stage
- Drafter colocated with verifier logits
- Fewer feedback hops → less communication overhead
- Need a separate copy of embedding layer, but it's tiny (~1% of model size)
Additionally, to support EAGLE3’s need for mid-layer activations, we:
- Captured hidden states during forward pass at layers 2/19/29
- Forwarded them to the last stage via shared memory or async send
- Buffered them for speculative decoding without affecting verification
This required precise control over:
- Layer partitioning
- Memory allocation
- Inter-stage synchronization (without stalling the pipeline)
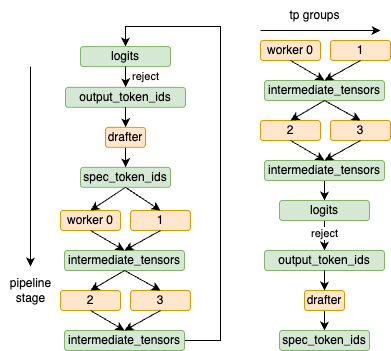
🔄 Async Pipeline Saturation
To fully utilize all pipeline stages, we extended the executor and scheduler to support multi-batch execution:
- Scheduler: Tracks requests already in-flight; avoids re-scheduling
- Executor: Uses async message passing and futures to avoid blocking
- Workers: Ready to process next batch as soon as upstream output is available
This dramatically improved throughput once multiple batches were queued, especially for long sequences or low acceptance rates in speculative decoding.
🧪 Summary of Design Insights
| Feature | Challenge | Our Solution |
|---|---|---|
| Pipeline parallelism | Blocking communication | Decentralized, async messaging |
| Speculative decoding | Feedback loop + activations | Drafter at last stage + mid-layer capture |
| Drafter placement | Embedding reuse | Copy lightweight embedding layer |
| Batch saturation | In-flight duplication | Asynchronous scheduler + batch memory tracking |
This system design demonstrates not only the feasibility of combining speculative decoding with pipeline parallelism—but also the engineering effort required to make it performant, modular, and compatible with evolving LLM architectures like EAGLE3.
Would you like a visual system diagram or architecture flowchart to include alongside this blog section?
📊 Key Results
We benchmarked our implementation using:
- LLaMA-3.1 8B and 70B models
- MT-Bench, HumanEval, GSM8K, Alpaca, and CNN/DailyMail datasets
- vLLM 0.8.5, Torch 2.6, CUDA 12.2, on 8x H100 GPUs
🚀 Speculative Decoding + Pipeline Parallelism
| Setup | Acceptance Rate | Avg Accepted Length | Throughput | Latency |
|---|---|---|---|---|
| LLaMA-8B + Eagle3 (1D, 1P, 1T) | 0.51 | 3.34 | 11.7k tok/s | 1.37s |
| LLaMA-8B + Eagle3 (1D, 2P, 2T) | 0.51 | 3.33 | 15.5k tok/s | 1.91s |
- EAGLE3 consistently outperforms EAGLE1 in both acceptance rate and length.
- Even with increased pipeline stages, speculative decoding retains performance.
- Latency remains lowest at small batch sizes—validating Eagle3’s design.
🔁 3D Parallelism Insights
| Model | Data | Pipeline | Tensor | Best Config |
|---|---|---|---|---|
| 8B | ✅ | ✅ | ✅ | (1D, 1P, 8T) |
| 70B | ❌ | ✅ | ✅ | (1D, 1P, 8T) |
- Tensor parallelism is the most effective strategy for intra-node setups due to fast NVLink collective operations.
- Data parallelism, surprisingly, suffers from CPU contention and can hurt performance without careful thread management.
- Pipeline parallelism alone provides limited gains unless combined with async scheduling.
💡 Takeaways
- Speculative decoding and pipeline parallelism are compatible—but require thoughtful system-level design.
- For large models, pipeline + tensor parallelism is necessary to enable inference at all.
- For small models, intra-node tensor parallelism often gives the best speedup.
- NVLink enables super-efficient collective ops, making tensor parallelism highly favorable in single-node setups.
- With more fine-tuning (e.g., fixing CPU contention in DP), multi-strategy hybrid setups may perform even better.
🧪 Try It Yourself
We are preparing a public release of our code with detailed docs and examples. Our goal is to upstream the changes to vLLM once we complete additional validation.
Stay tuned on GitHub!
📚 References
This work builds upon prior research and tooling:
🔧 Acknowledgements
We thank the maintainers of vLLM and the authors of EAGLE for their open-source work, which enabled our research. This project was completed using limited compute resources on a single node with 8x H100s and demonstrates what’s possible with careful engineering.